PythonのBeautifulSoupを使ったテーブルデータ取得
PythonのBeautifulSoupを使ってテーブルデータを抜くソースコード公開
最近IPO(新規上場株)関連のWEBアプリケーションを作ろうとしています。その際に効率的にコンテンツの情報を集めるために充実した外部Webサイトのデータを抜き出そうと考え,PythonのBeautifulSoupを使ったデータ取得アプリを作ったので今回記事にしていこうと思います。当然ソースコードも紹介していますし,IPOが分からなくても全く問題ないので是非見てください。
最初にPythonのBeautifulSoupを簡単に紹介すると特定URLのページを構成するHTML要素からデータを便利に抜くことができるライブラリです。ちなみに以前にもBeautifulSoupの記事は書いていたのでこちらのページも興味があれば是非見てください。
今回はIPO関連でSEO上位に入っている方のWebサイトから証券会社ごとの割当株数をテーブルデータから抜き出していこうと思います。なお,IPOとか言っていますがソースコードの理解には関係ないです。
今回は室町ケミカルのページからデータを頂戴したいと思います。色々なコンテンツが充実して書いてありますが今回は新規に発行される株式をどの証券会社が何株ずつ引き受けるかのテーブルデータを取得しようと思います。
ちなみにそのテーブルデータはページ中腹部~下腹部に書いてあります。
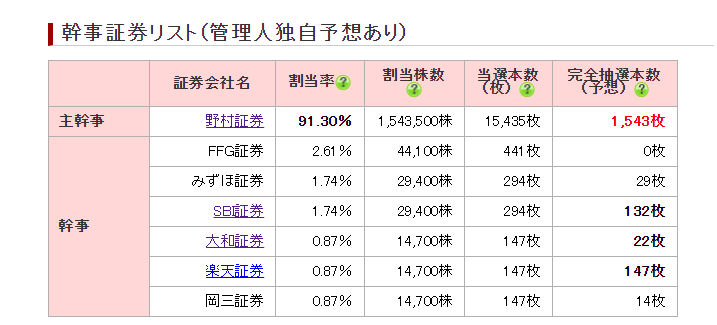
この中で証券会社ごとの割当率と割当株数を取得したいと思います。その場合,まずソースコードを組む前にHTMLの構造を確認する工程から始めます。そのため調べたいページで右クリックをしてソースコードの表示を押してください。
そうするとそのページを構成するHTMLの構造を確認する事ができます。色々と書いてありますがこれはHTMLとJavascriptで構成されています。

ここで確認するのは取得したい項目にid,classが付いているかいないかです。このid,classがあるかないかでプログラミングの手間は大きく変わります。ちなみにid,classがある方がプログラミングは楽ですし,基本的にid,classは付いている事が多いです。今回調べたいテーブルのところのソースコードを確認すると以下のようになっていました。
<table class="kobetudate04">
<tr>
<th class="side01"> </th>
<td class="back-pink bold f-gray side02" align="center">証券会社名</td>
<td class="back-pink bold f-gray side03" align="center">割当率<a title="header=[割当率(わりあてりつ)] body=[IPO株が証券会社に何%配分されたかがわかる数字。割当率が高い方が配分が多く当たりやすい。] hideselects=[on]"><img src="/company/image/question.gif" alt="?" width="15" height="15"></a></td>
<td class="back-pink bold f-gray side04" align="center">割当株数 <a title="header=[割当株数(わりあてかぶすう)] body=[証券会社に割り当てられる株数(推定値)。「すべてのIPO抽選株数×割当率」で計算される] hideselects=[on]"><img src="/company/image/question.gif" alt="?" width="15" height="15"></a></td>
<td class="back-pink bold f-gray side05" align="center">当選本数<br>
(枚) <a title="header=[当選本数(とうせんほんすう)] body=[純粋な当たりの本数。100株単位の場合は、「割当株数÷100(株)」で計算される] hideselects=[on]"><img src="/company/image/question.gif" alt="?" width="15" height="15"></a></td>
<td class="back-pink bold f-gray side06" align="center">完全抽選本数<br>
(予想) <a title="header=[完全抽選本数(かんぜんちゅうせんほんすう)] body=[当選本数の中でも、ネット抽選で公平に配分される本数(推定値)。] hideselects=[on]"><img src="/company/image/question.gif" alt="?" width="15" height="15"></a></td>
</tr>
<tr>
<th>主幹事</th>
<td width="200"><a href="/security/nomura.html">野村証券</a></td>
<td width="72"><b>91.30%</b></td>
<td width="95">1,543,500株</td>
<td width="72">15,435枚</td>
<td width="72" class="red-bold">1,543枚</td>
</tr>
<tr>
<th rowspan="9">幹事</th>
<td>FFG証券</td>
<td>2.61%</td>
<td>44,100株</td>
<td>441枚</td>
<td>0枚</td>
</tr>
<tr>
<td>みずほ証券</td>
<td>1.74%</td>
<td>29,400株</td>
<td>294枚</td>
<td>29枚</td>
</tr>
<tr>
<td><a href="/security/sbi.html">SBI証券</a></td>
<td>1.74%</td>
<td>29,400株</td>
<td>294枚</td>
<td><b>132枚</b></td>
</tr>
<tr>
<td><a href="/security/daiwa.html">大和証券</a></td>
<td>0.87%</td>
<td>14,700株</td>
<td>147枚</td>
<td><b>22枚</b></td>
</tr>
<tr>
<td><a href="/security/rakuten.html">楽天証券</a></td>
<td>0.87%</td>
<td>14,700株</td>
<td>147枚</td>
<td><b>147枚</b></td>
</tr>
<tr>
<td>岡三証券</td>
<td>0.87%</td>
<td>14,700株</td>
<td>147枚</td>
<td>14枚</td>
</tr>
</table>
この<table>から</table>の中身で先ほどの証券会社,割当率と割当株数が入っています。この中からデータを取り出していこうと思います。まず,気にして頂きたいのは一番上の<table class=”kobetudate04″>の部分です。この”kobetudate04″でこのtableデータを区別してくれています。そのためBeautifulSoupを使う場合,この”kobetudate04″を対象にデータを取得すればいいのです。
特定のclassを指定してtableデータをBeautifulSoupで取得
まず,データを取得するソースコードを以下に書いておきます。
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# URLの指定
html = urlopen("https://www.ipokiso.com/company/2021/muro-chem.html")
bsObj = BeautifulSoup(html, "html.parser")
# テーブルを指定
table = bsObj.findAll("table", {"class":"kobetudate04"})[0]
rows = table.findAll("tr")
print(rows)
こんな形でデータを取得します。table = bsObj.findAll(“table”, {“class”:”kobetudate04″})[0]のところですが,確認したところこのWebページには”kobetudate04″が複数あったので,今回取得したい情報が一番上だったため[0]を指定しています。まぁ雰囲気で分かるとは思いますが
- tableという変数に”kobetudate04″の”table”情報を格納する。
- table変数の中から”tr”タグで分割されたデータを取得する
という処理をしています。ちなみに出力されるデータは以下の通りです。
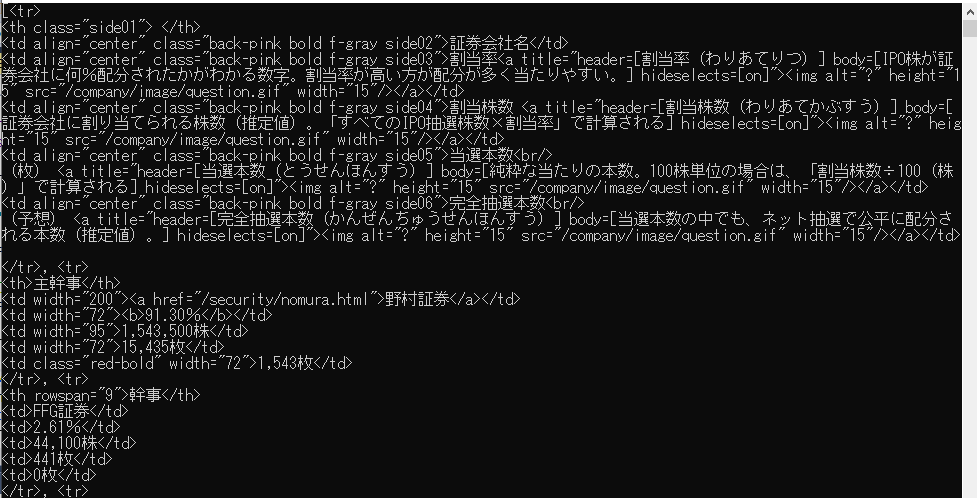
ぱっと見た感じ,ちゃんと欲しいtableのデータを<tr>~</tr>というタグの中身を取得できてますね。ただ<tr>タグで切り分けているので入っているデータは大雑把ですよね。
そこで<tr>タグよりも細かくデータを見るために<td>タグでコンテンツを分解していきます。
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# URLの指定
html = urlopen("https://www.ipokiso.com/company/2021/muro-chem.html")
bsObj = BeautifulSoup(html, "html.parser")
# テーブルを指定
table = bsObj.findAll("table", {"class":"kobetudate04"})[0]
rows = table.findAll("tr")
for row in rows:
tdrows = row.findAll("td")
for tdrow in tdrows:
print(tdrow)
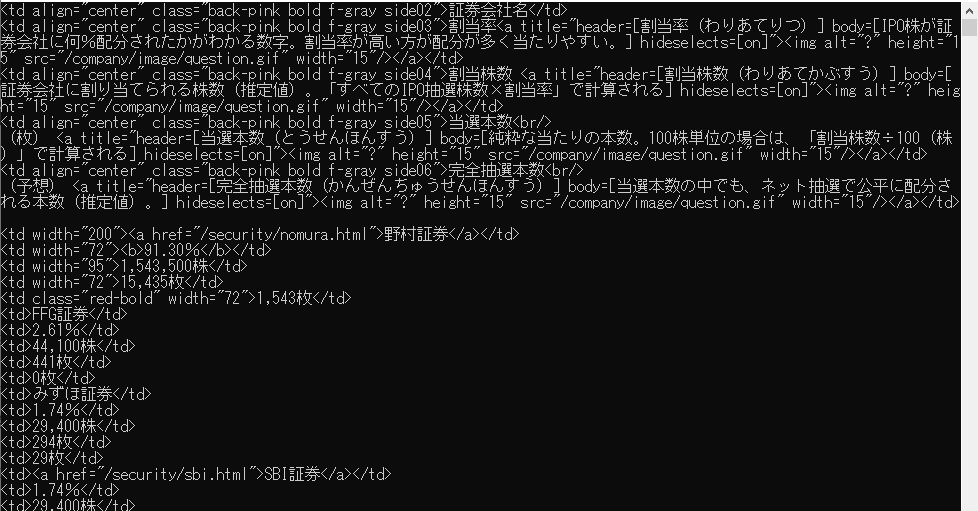
少し綺麗になりましたね。特に下の方は会社名とパーセンテージ,株数などを分割して取得できていますね。
不要な部分を削除するソースコードを追加
ただコマンドプロンプトの上半分の情報は丸々要らないですよね。そのため今回のケースだと証券会社の名前が出てくるまでデータを取得しないようにすれば,上半分のデータは切り離す事ができます。またパーセンテージ(%)と株数以外の情報は不要のため,切り離すためのソースコードを少し改修しましょう。
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
def checkTarget(tdrow):
if 'SBI証券' in tdrow:
return 'SBI証券'
elif '大和証券' in tdrow:
return '大和証券'
elif 'SMBC日興証券' in tdrow:
return 'SMBC日興証券'
elif 'スタンレー証券' in tdrow:
return 'モルガンスタンレー証券'
elif 'フレンド証券' in tdrow:
return 'フレンド証券'
elif 'みずほ証券' in tdrow:
return 'みずほ証券'
elif '楽天証券' in tdrow:
return '楽天証券'
elif '岡三証券' in tdrow:
return '岡三証券'
elif '野村証券' in tdrow:
return '野村証券'
elif '丸三証券' in tdrow:
return '丸三証券'
elif 'いちよし証券' in tdrow:
return 'いちよし証券'
elif 'FFG証券' in tdrow:
return 'FFG証券'
else:
return '該当なし'
# URLの指定
html = urlopen("https://www.ipokiso.com/company/2021/muro-chem.html")
bsObj = BeautifulSoup(html, "html.parser")
# テーブルを指定
table = bsObj.findAll("table", {"class":"kobetudate04"})[0]
rows = table.findAll("tr")
Trigger = False
for row in rows:
tdrows = row.findAll("td")
for tdrow in tdrows:
temp = checkTarget(str(tdrow))
if '該当なし' in temp:
if Trigger == True and '株' in str(tdrow):
print(tdrow)
elif Trigger == True and '%' in str(tdrow):
print(tdrow)
else:
print("**************************************************")
Trigger = True
print(temp)
このソースコードではTriggerという判定を用意し,会社名に合致する項目名が出てきたときからTriggerがFalse⇒Trueになり,データを表示する処理に入ります。そのため不要な上半分とパーセンテージと株数以外が消えた出力画面になります。
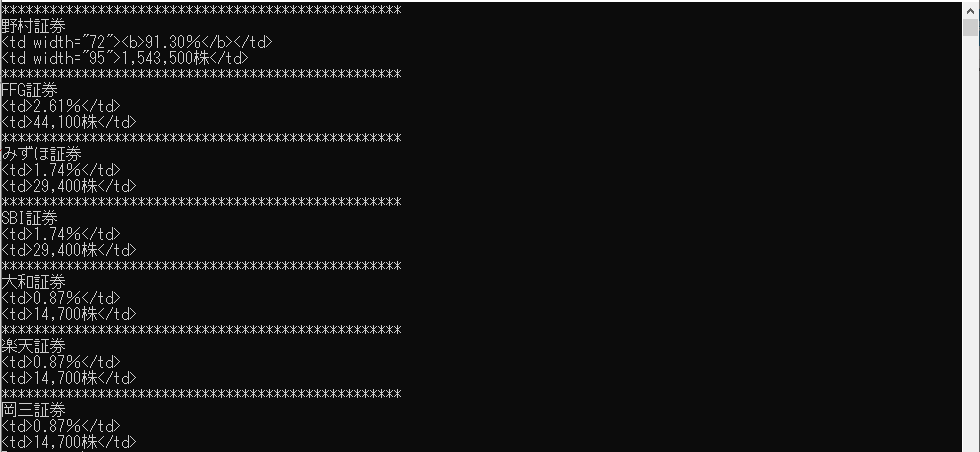
はい,綺麗になりましたね。正直会社名のマッチング処理はかなり汚いですがまぁサンプルプログラムなのでOKとしましょう。ただ,これだとパーセンテージと株数のところに<td></td>のように無駄な部分が入っていますのでタグを排除する処理を追加する必要があります。ではそれを追加した処理を以下に記載します。
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
def checkTarget(tdrow):
if 'SBI証券' in tdrow:
return 'SBI証券'
elif '大和証券' in tdrow:
return '大和証券'
elif 'SMBC日興証券' in tdrow:
return 'SMBC日興証券'
elif 'スタンレー証券' in tdrow:
return 'モルガンスタンレー証券'
elif 'フレンド証券' in tdrow:
return 'フレンド証券'
elif 'みずほ証券' in tdrow:
return 'みずほ証券'
elif '楽天証券' in tdrow:
return '楽天証券'
elif '岡三証券' in tdrow:
return '岡三証券'
elif '野村証券' in tdrow:
return '野村証券'
elif '丸三証券' in tdrow:
return '丸三証券'
elif 'いちよし証券' in tdrow:
return 'いちよし証券'
elif 'FFG証券' in tdrow:
return 'FFG証券'
else:
return '該当なし'
# URLの指定
html = urlopen("https://www.ipokiso.com/company/2021/muro-chem.html")
bsObj = BeautifulSoup(html, "html.parser")
# テーブルを指定
table = bsObj.findAll("table", {"class":"kobetudate04"})[0]
rows = table.findAll("tr")
Trigger = False
for row in rows:
tdrows = row.findAll("td")
for tdrow in tdrows:
temp = checkTarget(str(tdrow))
if '該当なし' in temp:
if Trigger == True and '株' in str(tdrow):
print(tdrow.get_text())
elif Trigger == True and '%' in str(tdrow):
print(tdrow.get_text())
else:
print("**************************************************")
Trigger = True
print(temp)
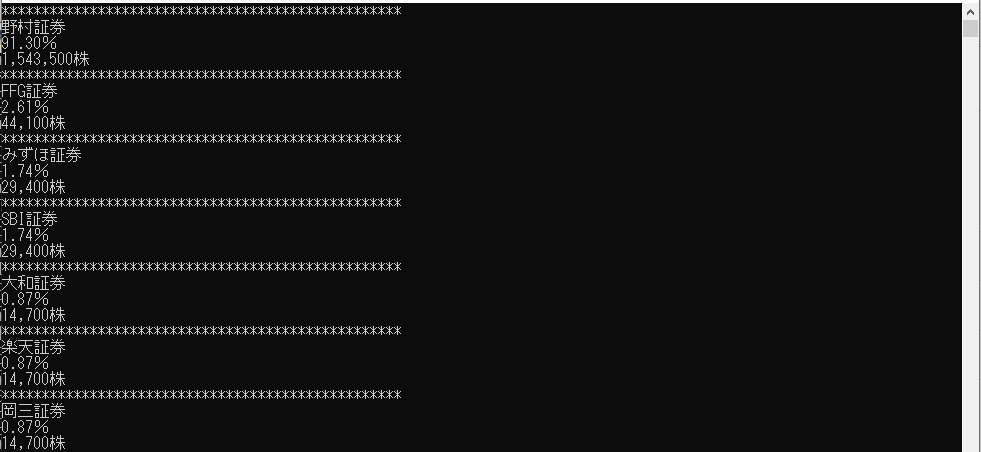
はい,綺麗になりましたね。tdrow.get_text()の部分でタグを排除した内容を取得する事ができます。これで綺麗に欲しい情報を取得できるようになりました。
如何だったでしょうか。終わってみれば大したことのないプログラムだったと思います。一方である程度Webサイトに合わせた処理を追加しなければいけないのでコーディングに慣れない人はつまづきやすいかも知れませんね。
今後もWebサイト関係やIPO関係の情報を発信していきますので是非他の記事も見ていってください。
