[python]機械学習のデータ収集と前処理方法(プログラミング含む)
Pythonを使った機械学習の事前準備 データ収集と前処理紹介(プログラミングも含む)
こちらの記事をお読みいただいている方は恐らく・機械学習に興味がある もしくは ・機械学習を使ったシステム開発をしているが上手くいかないところがある 方だと思います。そういった方々に本記事の内容が少しでも助力になれば幸いに思います。
なお,今回は機械学習の事前準備について記載します。機械学習とは何かについては以下の記事を参照願います。リンク先では機械学習の基本部分について解説しております。
機械学習のシステムが毎月のように新しく出ており,各社で活発に開発されている事が分かります。しかし機械学習を開発し,AI予測の精度を高めていくにはただ機械学習のシステムを回すだけでなく,学習データのデータ収集と集めたデータに対する前処理が重要になります。

この記事ではデータ収集および収集したデータの機械学習の前処理方法を紹介していきます。
機械学習に必要なデータ収集 基本フォーマット
機械学習を行う上で当然必要になるのは学習データです。データがない事には予測も何もありませんからね。
一方で機械学習を行う上でのデータ収集方法に決まった方式はあるのでしょうか。先にこの問題に対する答えを書くと「明確な答えはありません」というのが真実になります。それだと皆さんも「えぇ?」と思うかもしれませんが,決まった答えではなくとも学習させやすいテンプレートのようなフォーマットは存在するのでご安心ください。
今回のデータ収集の参考例として,以前私が集めたIPO(上場時新規公開株)のデータについてCSVフォーマットにまとめましたのでそちらを使っていこうと思います。
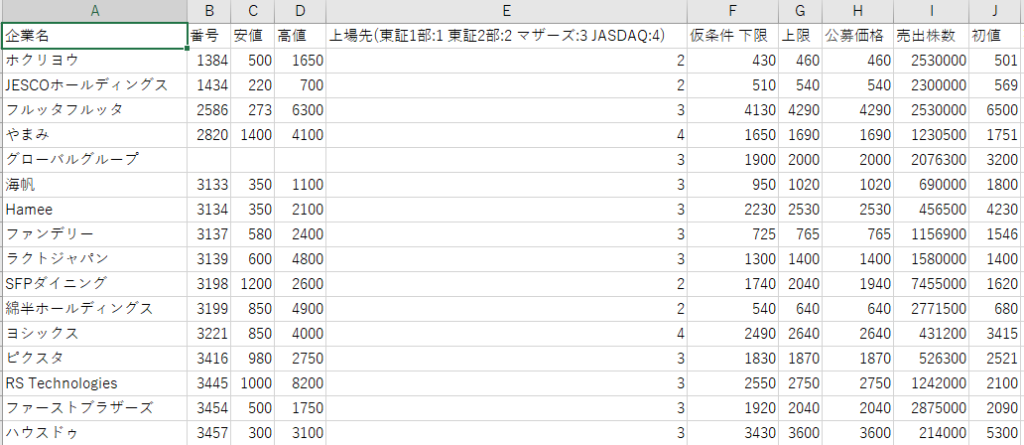
こんな感じでこれまで上場した会社のデータを各項目ごと(安値,高値や初値など)に横一列で記載してあります。これが正解!という並ばせ方ではないのですが,多くの機械学習では学習する前に必要なデータを横一列で取得しておく事が多いです。理由としては単純にデータとしてプログラム上に読み込む際に簡単なうえに人間的視点で見やすいからですね。
一方で企業名でグローバルグループと書いてある行に一部データがありませんね。B~D(番号,安値,高値)のデータがありません。これは抜けデータと呼び,機械学習を行う上で非常に大きな問題となります。
こういった問題のあるデータをなんとかするのが次に説明するデータの前処理になります。
学習データの前処理方法をPythonプログラミングを交えて解説
上記IPOのデータでは一部のデータが抜けてしまっている事が分かります。一方で機械学習はデータの抜けを許さず,エラーをはいてしまいます。つまりなんとかして空白を埋める必要があります。この空白を埋める行為をデータの前処理と呼んでいますので,これをPythonプログラミングを交えながら解説します。
まず,データの前処理方法には以下のパターンがあります。
- 空白データが存在する行を消してしまう(データの削除)
- 空白データに適当な数値をいれてしまう(欠損値の穴埋め)
それぞれのパターンで何をするのか,ここからPythonプログラミングの中でもデータ処理につよいライブラリであるPandasを使いながら解説していきます。
1. 空白データが存在する行を消してしまう(データの削除)
これは一番単純なパターンです。IPOのデータで抜けているデータが1つでも存在する行は削除する処理です。この場合最も簡易に問題を取り除けるので悪くはない選択なのですが,学習用のデータが少ない場合は消してしまうとAIによる予測に影響が出てしまいます。そのため使うのはデータが十分に存在する場合に限ります。ちなみに読み込んだデータから空白データを除いたデータを残す処理を以下に記載します。
import pandas as pd
df = pd.read_csv('IPO.csv') #dfという変数にIPOデータを入れる
detectdf = df.dropna(how = 'any',axis = 0) #dfの中からデータ欠損がある行を消す
print(detectdf) #削除後のデータを表示
なんとたったこれだけです。これだけで読みんだCSVデータの中から空白データが存在する行を自動的に消してくれます。
なお,出力データの一部(見切れてしまっています・・・)を以下に示します。
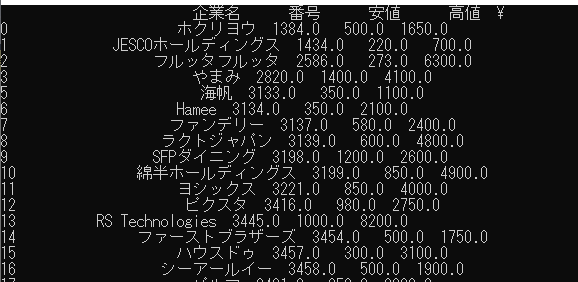
先ほど株式会社「やまみ」の下にグローバルグループというデータがありましたが行ごと消えている事が分かります。これが最も単純な「データの削除」です。
2. 空白データに適当な数値をいれてしまう(欠損値の穴埋め)
これも良く使われる手法で,空白データが存在して,データ数が少ない場合は適当な値を入れる事でごまかします。その際,通常出てくる値を入れてしまうとAIが勘違いを起こしてしまうので,とんでもない数字を入れる事が多いです。
この手法の弱点としては単純に予測精度に若干の悪影響を残す事です。まるで正しい情報かのように学習させるので当然ですね。
今回も参考プログラムを以下に記載していきます。今回のは若干面倒で,1列ずつしか穴埋めはできません。
import pandas as pd
df = pd.read_csv('IPO.csv') #dfという変数にIPOデータを入れる
df["番号"] = df["番号"].fillna(77777) #指定列の中の欠損値に77777を入れる
df["安値"] = df["安値"].fillna(88888) #指定列の中の欠損値に88888を入れる
df["高値"] = df["高値"].fillna(99999) #指定列の中の欠損値に99999を入れる
print(df) #穴埋め後のデータを表示
各列ごとに空白データに指定の値を入れていく処理になります。今回は3か所のデータが抜けているグローバルグループにそれぞれ77777,88888,99999を入れたところ,以下のような結果になりました。
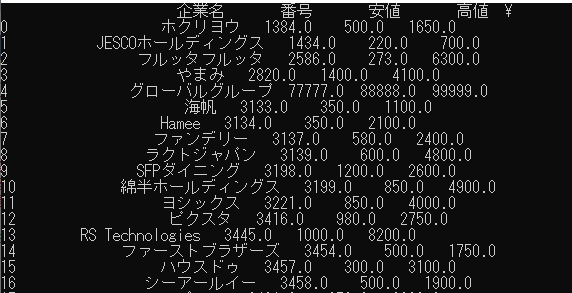
4番目にちゃんとグローバルグループが存在し,77777,88888,99999がちゃんと入っていますね。これでとりあえず機械学習システムにデータを入れられる事が分かります。
このようにして機械学習を実施できるようにデータの前処理を行っていきます。
特に欠損値の穴埋めなどは機械学習をやっていれば大抵やる事になりますので,穴埋め方法を理解しておくとスムーズに進められると思います。
