[IPO] AIによるIPO初値予測のプログラミング
PythonによるIPO初値のAI(機械学習)予測
前回の記事でランダムフォレストによるIPO初値に対する多変量分析を表示しました。今回はそれをやるまでの流れを書きますので是非ご参考頂けると幸いです。
まず,Pythonによる分析をする際にcsvデータフォーマットでデータを横一列にまとめるのがオススメです。基本的に仕事などでデータ分析する際はデータベースサーバからデータを取得するのが多いと思いますがサーバへの処理負荷を下げるために一度csvファイルに落としてから分析したほうが良いです。
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pickle
df = pd.read_csv("IPO.csv", encoding="shift-jis")
x = df.iloc[:,0:46] #説明変数 0列目から45列目までがまるっと入ります
y = df.iloc[:,46] #目的変数 46列目のデータが入ります
print(y) #目的変数がしっかり入ったか目視確認用
from sklearn.multioutput import MultiOutputRegressor
clf = RandomForestRegressor(n_estimators=20, random_state=300) #機械学習のアルゴリズム選択
clf.fit(x, y) #機械学習部分 データ量に応じて時間がかかる
AA = [] #パラメータ名称を日本語で付けたのでヘッダーからではなく手打ちする
######################################
AA.append('Stage')
AA.append('LowLimit')
AA.append('HighLimit')
AA.append('StrikeValue')
AA.append('StockAmount')
AA.append('Industry')
AA.append('Sale_5')
AA.append('Interest_5')
AA.append('NetIncome_5')
AA.append('NetAssets_5')
AA.append('AssetsOfOne_5')
AA.append('IncomeOfOne_5')
AA.append('Capital_5')
AA.append('Equity_5')
AA.append('Sale_5')
AA.append('Interest_5')
AA.append('NetIncome_5')
AA.append('NetAssets4')
AA.append('AssetsOfOne_4')
AA.append('IncomeOfOne_4')
AA.append('Capital_4')
AA.append('Equity_4')
AA.append('Sale_3')
AA.append('Interest_3')
AA.append('NetIncome_3')
AA.append('NetAssets_3')
AA.append('AssetsOfOne_3')
AA.append('IncomeOfOne_3')
AA.append('Capital_3')
AA.append('Equity_3')
AA.append('Sale_2')
AA.append('Interest_2')
AA.append('NetIncome_2')
AA.append('NetAssets_2')
AA.append('AssetsOfOne_2')
AA.append('IncomeOfOne_2')
AA.append('Capital_2')
AA.append('Equity_2')
AA.append('Sale_1')
AA.append('Interest_1')
AA.append('NetIncome_1')
AA.append('NetAssets_1')
AA.append('AssetsOfOne_1')
AA.append('IncomeOfOne_1')
AA.append('Capital_1')
AA.append('Equity_1')
# 特徴量重要を抽出
feature_importance = clf.feature_importances_
## pandas.Dataframeに変換
feature_importance = pd.Series(feature_importance,index=AA)
#実際に可視化する ここでブレークポイントを置かないと可視化に失敗する
feature_importance.sort_values().plot(kind='barh', figsize=(10, 4), color='aquamarine')
#pickleを作成し,今後はpickleから予測モデルを読み出す
with open('IPO.pickle', 'wb') as f:
pickle.dump(clf, f)
上のソースコードで読み取っているIPO.csvは以下のフォーマット
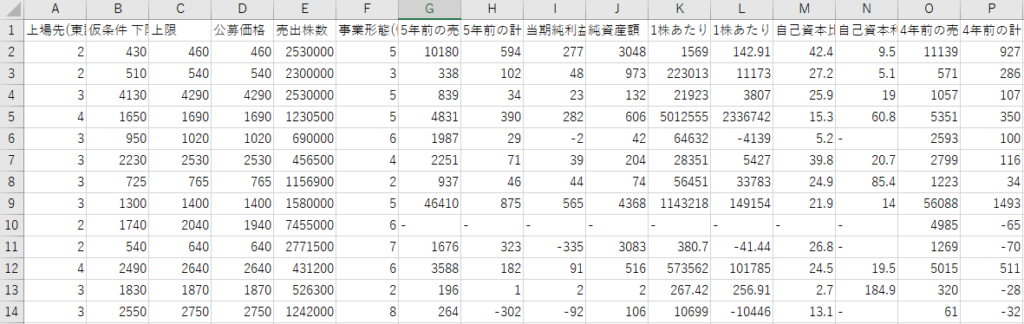
このファイルの46列目に初値の情報を入れておきます。また実行する.pyファイルと同じフォルダにIPO.csvという名前で保存しておかないとエラーが出ますので気を付けてください。
そして他の記事でも書きましたが出てきた特徴量がこれです。
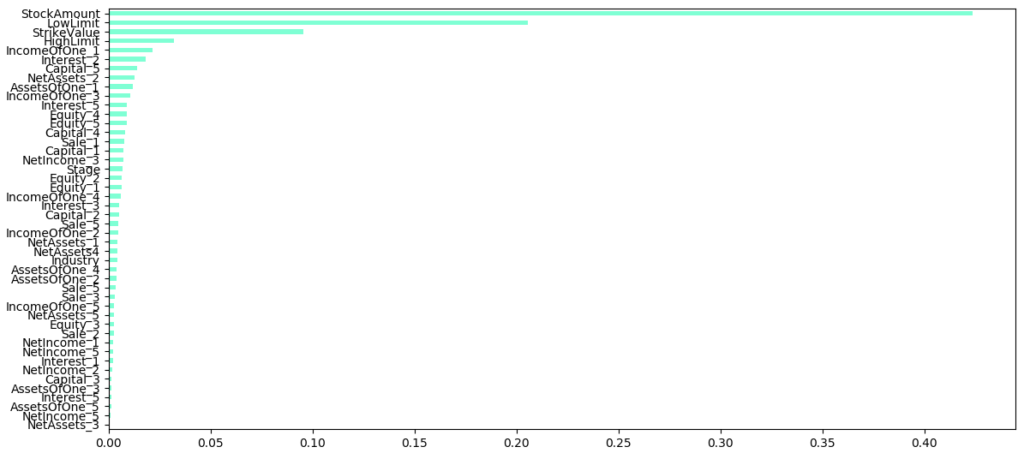
Stock Amount(発行株数)でほとんど決まるようですね。一応公募価格とかも効いていそうですが仮条件の上限いかないIPO株とか基本買わないですしあまり役には立ちません。
今回初めてソースコード載せましたが表示は20行で折り返しとかできないんですかね・・・?いいやり方あったら教えて欲しいです。
