[IPO]新規公開株の過去データ整理終了!
AI(機械学習)によるIPO初値変動を予測する準備完了
すごい長い事データ収集と整理をしておりましたがついに機械学習に必要なデータをまとめ終わりました。
総作業時間は20時間くらいでしょうか。これを会社終わりとかにやるんですからモチベーション維持が大変でした
部分的なデータを見せますが全113社の過去上場時のデータをまとめています。すべてPDFからデータを探したのでこれだけで相当IPOの値段上昇や人気の出る条件などはかなり把握できました。
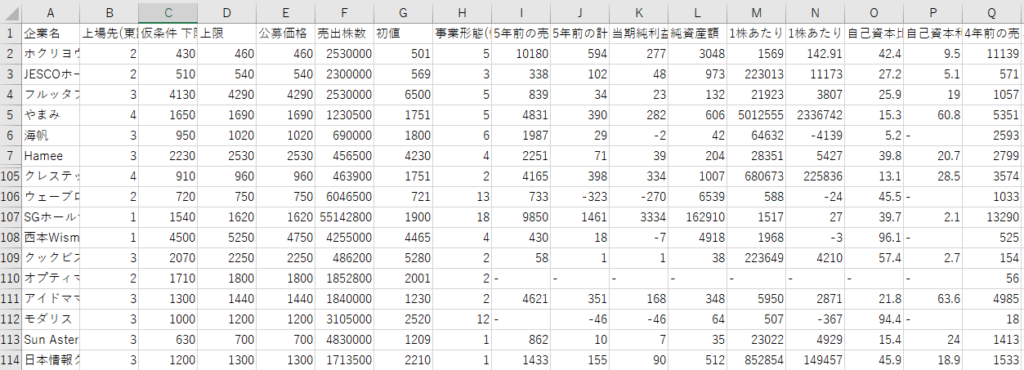
全てのデータをcsvファイルでまとめていますが2行目から114行目までで113社分です。WEBからスクレイピングとかでこういった情報を拾う方法あったら誰か教えてほしいです。
そしてこのデータをランダムフォレストによる多変量分析した結果が次になります。なお,G列の初値に対する多変量分析で,英語にしないと文字化けするため適当な単語に変換しています。変換表は下図の通りです(こちらから拝借しました。本当にありがとうございます。)。

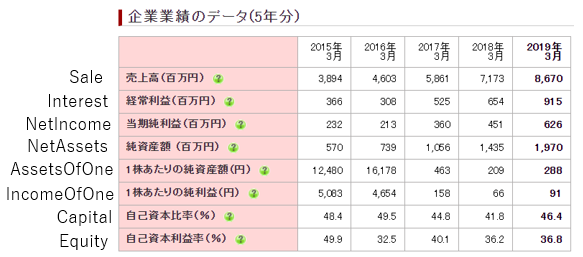
- Stageは上場先(東証1部:1 東証2部:2 マザーズ:3 JASDAQ:4)
- Industry : 業種 (主が事業内容を目論見書から確認して分類しているため不確定要素)
- SaleやInterestに関しては5期前をSale_5, 1期前をSale_1として表記。数字が若いほど新しい業績
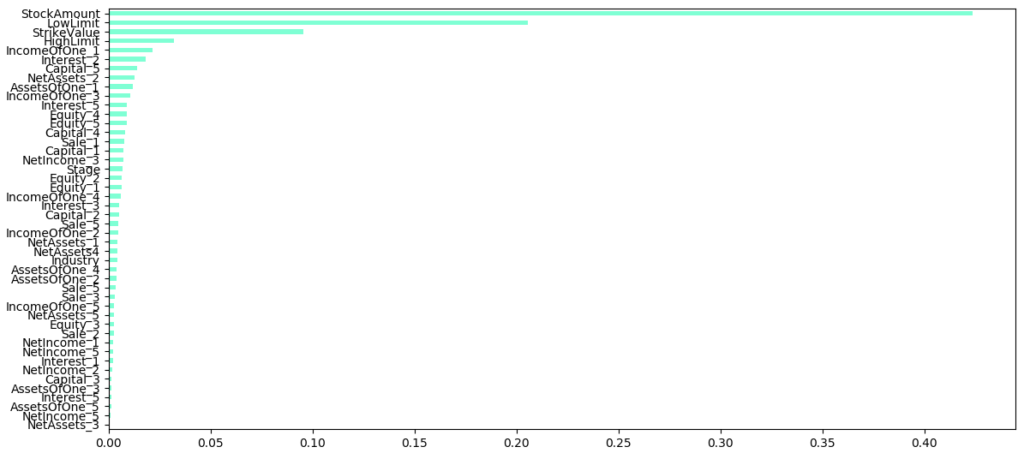
このランダムフォレストの多変量分析は学習させた複数パラメータの中で寄与度が大きい物順に出してくれます。今回の場合,StockAmount(発行株数)が初値の増減に一番大きく影響し,LowLimit(公募価格の仮条件下限)が次点で影響している事を示しています。なお,LowLimitの次はStrikeValue(公募価格)なので,おそらくLowLimitとStrikeValueの差分が重要だと示しているようです。(まぁ予想通りですね)
これを元にIPOの初値を予測するAIを作ろうと思います。本来は機械学習のアルゴリズムごとの精度比較などをすべきなのですが面倒なのでこのままランダムフォレストで作ります。
ランダムフォレストによる分析を含むプログラミングのソースコードは別ページにて紹介します。
